2013-08-14
intersect.husk.org - a writeup
Ever since Twitter hid at-replies from people who weren't mutual followers, I've had cause to wonder how many people are seeing the conversations I seem to be taking part in.
I remember, even just a couple of years ago, there being a few web sites that let you put in two usernames and see who was following both, but there are two problems with that:
- They were usually really badly designed
- I couldn't find any of them recently
- they never did seem to like the fact that my main account is protected
That being the case, I thought it'd be a good little project to hack on. Fetching and calculating the overlap was pretty straightforward, and I had the idea that I'd like to represent the followers of both users, along with their overlaps, with a Venn diagram. It wasn't too hard to get this drawing with d3, but it took a while to completely straighten out all of the maths.
Once I had the app up and running, I found the real reason there probably aren't any of these services any more: Twitter's API rate limits. In particular, intersect makes a lot of use of the /follower/ids call - understandably, since the whole point is the overlap of followers - which gets 5,000 followers at a time, but is limited to 15 calls per 15 minute window.
What does this mean for a user? Well, if you're following normal-ish people, then you can only look up a few of them every quarter of an hour. After that, the app echoes the error Twitter returns: 'rate limit exceeded'. If you try someone with hundreds of thousands of followers, the app will just fail.
I've thought about putting in a counter, either raw or as a percentage, and also of detecting users who'd require more than a few calls to /followers/ids/ and refusing to work for them. (Alternatively, I could only consider their most recent ten thousand users. I may yet do that.)
For now, though, I seem to have reached a point where I'm happy to stop writing code, finish this write-up, and let the app hang out on Heroku for as long as it wants. If you're curious about the code, it's on Github. Meanwhile, I can happily check that when I have a spirited conversation with @whoisdanw, only sixteen people are likely to be subjected to it.

(Oh, and thanks to Fiona Miller, who did some sterling work on colours, as well as thinking through user interactions, and Tom Insam, who came up with the good idea of colouring the users to match the circles representing their follower counts. They were invaluable in making the site look lovely.)
2012-03-27
More Thoughts On Pagination
For the last month or so, Flickr have been starting to roll out their new "justified" view across the site. It's very pretty, and generally I'm a fan, but as well as the possible criticism of the reliance on JavaScript,¹ it's meant that the easy access to page numbering on the old views has been lost. An off-the-cuff (and admittedly somewhat snarky) remark on Twitter prompted Nolan Caudill to write a well-thought-out post about pagination.
In it, he agreed with my point about infinite scrolling:
Infinite scrolling is basically a pretty representation of the 'next' link that you 'click' by scrolling to the bottom of a page. I'll leave whether or not it's good user experience to others, but as a purely visual experience, I like it. If it's the only source of pagination, that sucks, and another navigation scheme should be provided if having your users be able to look through the list or find something is important.
but he also made a very good point about the failings of traditional "n per page" links:
Pagination should provide accurate navigation points that reflect the overall ordering of the stream, and pagination based around fixed-length pages provide nothing more than arbitrary access into this ordering, where we have to use estimation and instinct about the distribution of the content in order to make a guess of where a link will send us
He goes on to suggest time-based navigation, somewhat like the letter tabs often found in dictionaries. In fact, many sites already implement their APIs this way- Flickr included. Twitter makes copious use of max_id (and this is well-explained in their documentation), while Instagram use max_timestamp and min_timestamp. There are places in the Flickr API that can use min_timestamp and max_timestamp, although there are also traditional page parameters in that call.
It's not just APIs, though. Tumblr's archives are infinite-scroll, but with a month selector so you can skip back and forth through time. (That's on the desktop web, anyway: for some reason the iPad version omits the form.) It's not perfect - if you post hundreds (or thousands) of entries in a month, it's hard to pick them out - but for most users, it works fairly well.
Of course, having said all this, I should really implement something that mixes the visual niceness of justified view with the navigational panache of a timeline. One thought I did have is that a small (sparkline-style?) bar graph of posts over time, although computationally expensive across large archives, would definitely help to highlight busy points to look at (or, depending on whether your friends upload too many photos from trips, avoid). Definitely something to consider playing with.
¹ Oops: I didn't test this, but Stephen Woods correctly pointed out that JavaScript is only used to delay loading and extend the number of photos shown, and that the page works fine with JS disabled. ↩
2010-01-28
Introducing docent
Flickr and galleries
It's now a little over four months since Flickr launched their galleries feature. I liked it as soon as I saw it: it's taken a frequent request ("how can I have sets of favourites?") and delivered something that does the same job, but in a different way. I know some people quibble about some of the constraints, but I like the limited number of photos you're allowed, and generally I've enjoyed creating and browsing them.
Unfortunately, there's a problem: discovering other people's galleries. Aaron Straup Cope is good at bookmarking them on delicious, and there's an Explore page, but neither of those necessarily find things I'd like to see.
The gist of it
Just over three weeks ago, Kellan announced the first API support for galleries, and I quickly created a Python script that would go through all my contacts and fetch their galleries. It was useful, and it turned up a lot of galleries I hadn't seen, but it had two big flaws: nobody else would use it, and it wasn't pretty.
App Engines and data models
I've used App Engine in the past, but that was before the advent of their experimental Task Queue API, and I didn't use the datastore. Using Aaron's gae-flickrapp as a core, I spent about a week's worth of evenings on and off learning how to use both, ending up with the core of docent¹, a small web app.
There are only four kinds of object: dbFlickrUser, from gae-flickrapp, which handles logged in users; Contacts, which have a one-to-one relationship with dbFlickrUsers; FlickrUser, which is an object for a user docent knows about but who isn't necessarily logged in; and Gallery, which stores information about the gallery itself.
What it does
When you first log in, a task is added to a high-priority queue to fetch your contacts from Flickr. The NSIDs² from this call are stored in a single ListProperty in the Contacts object, and then a new task is added to a lower-priority queue. This goes through the IDs one by one, fetching the galleries Atom feed³ and creating the relevant objects (if necessary). This, and the various tasks to update galleries for older users, make up the bulk of the CPU load of the app, and almost all of the Datastore writes.
The big difference between traditional ORMs and the way I'm using the App Engine datastore comes into play here. In an ORM such as Django, a dbFlickrUser would have a many-to-many relationship with FlickrUsers, which would then have a one-to-many relationship with Galleries. The former would require a join table between them. The query to fetch all galleries from a single user would look something like galleries = Gallery.objects.filter(owner__contact_of__nsid=nsid)
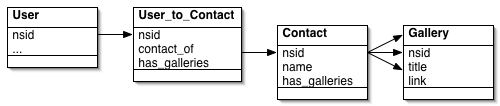
By contrast, in the datastore, Both FlickrUser and Gallery objects have a contact_of ListProperty. As a new user's contact list is examined, their NSID is added to the contact_of list. This is how the pages showing galleries for a contact are built: it's a simple equality test, which is translated behind the scenes to a list-membership test:
galleries = Gallery.all().filter('contact_of =', nsid).fetch(256)
 It took a lot of fiddling to break out of the ORM/SQL mindset, based on joins, but I think I'm happier now I have. On the other hand, keeping the contact_of lists on all the objects in sync is something of an overhead, and the query code isn't significantly easier. There's also a rather severe limitation I only ran across later.
It took a lot of fiddling to break out of the ORM/SQL mindset, based on joins, but I think I'm happier now I have. On the other hand, keeping the contact_of lists on all the objects in sync is something of an overhead, and the query code isn't significantly easier. There's also a rather severe limitation I only ran across later.
Onto the Flickr blog
This was all well and good as I let a few other people at the site; initially close friends, then via a couple of screenshots on Flickr, before inviting a bit more of a burst of users via Twitter. The site seemed to be scaling fine; there was a lot of CPU used fetching contacts, which eventually I managed to optimise by being more selective about updating from the gallery feeds.⁴ In fact, the FlickrUser object is currently pretty much a stub, although I'm thinking of changing that.
However, when docent made the Flickr blog, it hit a serious issue: exploding indexes. The version of the app that was live was doing this query:
galleries = Gallery.all().filter('contact_of =', nsid)
.order_by('-published')
.fetch(offset, per_page)
That extra "order_by" criteria required an additional index, and because it's combined with a ListProperty (namely contact_of), it hit the problem documented in the Queries and Indexes page:
Custom indexes that refer to multiple properties with multiple values can get very large with only a few values. To completely record such properties, the index table must include a row for every permutation of the values of every property for the index.
When I last looked, docent knew about 14,000 or so galleries. While most had small contact_of lists, some no doubt expanded to dozens of people, and so the index was too large to store. As a workaround, I eventually realised I had to abandon sorting in the query and instead use Python, at which point the app started being responsive again. Lesson learnt, the hard way.
Moving On
So, what now? The app is up, and although there are a few errors still happening, they're mainly in background tasks that can be optimised and retried without any impact on users. Personally, it's been a fairly good, if occasionally intense, introduction to App Engine's unique features.
Would I do things this way again in future? I'm not sure. Turning the relationship model on its head hasn't led to an obvious improvement over the ORM+SQL methods I'd use in, say, Django, and while the Task Queue API is very easy to use, it's hard to develop with (since it has to be fired manually locally) and there are other job queue solutions (such as Delayed Job, for Rails, as used on Heroku). On the other hand, even with the heavy load, and not the best of optimisations, docent almost stayed within the App Engine free quota CPU limits⁵, and didn't approach any of the others.
In any case, I'm happy to have produced something so useful, and hope that anyone who tried using it yesterday only to run into errors feels willing to try again. In the meantime, I'm sure there'll be more scaling roadbumps as the site gains users and more galleries are added, but I'm looking forward to fixing them too. Please, try docent out.
(I know comments aren't enabled on this site at the moment. Feel free to add them on docent's page on Flickr's App Garden.)
¹ Why "docent"? Originlly it was the unwieldy gallery-attendant, but Chris suggested the name, based on a term more common in the US than here for the guide to a museum or gallery. ↩
² NSIDs feel like the primary key for Flickr users: in methods like flickr.people.getInfo, it's one of the key pieces of returned information, and it can be used in feeds to fetch information as well as URLs to photos and profile pages.↩
³ Using feeds rather than API calls can be handy. For one thing, they don't count against your API queries-per-second count; hopefully they're cached more aggressively, both via the feedparser library and on Flickr's side so they take less resources.↩
⁴ One nice thing about getting more users is that the likelihood of finding a contact's galleries in the data store already goes up. When I was developing, I had to fetch everything; for the second user, there was some overlap, saving calls. As the site gets bigger, the number of fresh gallery fetches should keep fairly low.↩
⁵ Since I last wrote about App Engine, it's grown the ability for users to pay for resources beyond the free quota levels. I decided to do this when I hit about 55% of my CPU quota, and the app did indeed reach about 120% yesterday. I don't have a bill yet but I expect it to be under $0.50, which is fine.↩
2009-06-09
Quick thoughts on iPhone 3GS
Well, I'm sold.
I've owned an iPod touch for eighteen months. At the time I didn't want to take a punt on the just-released iPhone, but in the intervening time the launch of the 3G hardware made me consider buying one. I'm disorganised, though, and when it got to April I decided to hold off, suspecting the hardware would be refreshed in June.
Of course, it has, and I'll soon be getting in touch with O2 to pre-order My First iPhone. I'm undecided on whether it's worth spending the extra for the 32GB model, but I probably will. The camera improvements (autofocus, slightly higher resolution, and video) are nice; I'm enough of a fanboy to cheer the compass (Google's Sky Map would be lovely), and of course it'll be nice to have a faster device. (Will games throttle their speed on the new hardware, I wonder?)
Existing owners of iPhones are a bit peeved, though. Unlike the last time there was an upgrade, O2 aren't doing anything to let people upgrade early, and operators everywhere seem keen to annoy people who want tethering, either by not offering it or overpricing it. Personally, I'm not that bothered. I know going in there's almost certainly going to be six months in late 2010 when I don't have the latest and greatest, and I dare say I'll cope. (As Matt Jones put it on Twitter, "if you like the shiny, don't be whiny.") A price cut in the UK would have been nice, but I suppose O2 don't feel they need it. Maybe if exclusivity ends?
(I also wonder if the loudest complainers are the same people who are used to upgrading their laptops with every speed bump? That's not a group I've ever been part of; instead, I aim to make my machines last at least their three years of AppleCare. Perhaps the first group are just more vocal, or more used to being able to buy what they want? Of course, iPhones aren't computers, but I assume people think of them as more like computers than phones.)
There is a subset of those vocal complainers who may have a point- developers. The iPhone platform now has devices that run the gamut from the first generation touch, which has no camera, Bluetooth, or support for microphones, to the iPhone 3GS, which has al of the above built in, plus the improvements noted above. The speed range is getting quite large too, and I can understand the desire of devs to get cheaper access to various bits of hardware.
For now, the best bet - outside of large companies - seems to be to find people to test things, but that's hardly the best approach. On the other hand, expecting Apple to duplicate Google's I/O stunt - handing out free phones to every attendee - wasn't likely either. I also wonder if Apple are expecting that developers will just use the emulator?
Still, for all the complaints - largely unjustified, as we all know telcos are like that - this is a perfectly good incremental update. As Steven Levy says, "It's not a game changer." It doesn't need to be, though, and I'm sure it'll do well.
2009-04-27
More on iPhoto '09 and Flickr
A couple of months ago, I posted some first thoughts on iPhoto '09 and its Flickr integration. Despite the fact that it's not amenable to scripting, I liked the idea of having photos be editable in either iPhoto or Flickr that I kept using the native support to upload photos.
Of course, as Fraser Speirs said, "iPhoto '09 really, really wants to make photosets for you." So how to upload a few images? Well, dragging an image adds it to a set, and as you'd hope, dragging images to an iPhoto set starts an upload going. However, there's a huge annoyance here: to get ordering in your photostream, you have to drop the images in one by one. (Flickr sets can be ordered post-upload, but you can't reorder your photostream¹.)
Generally, the syncing of metadata has been great- when I've changed a location (or even photo) it's worked fine. However, it's also been worryingly fragile. I think I've had issues about once a fortnight with an upload failing (either because of a temporary issue with Flickr, or network congestion, or just someone sneezing down the road). iPhoto then gets into a confused state. You can't abort the sync and quit; eventually it'll either crash of its own accord, or I'll get fed up and force quit. Upon restarting, I find it's forgotten which photos existed in the set, so it downloads the originals from Flickr and breaks the connection. Either that, or it just gives up.
At least the worst-case has never happened: iPhoto has never deleted a photo from Flickr without me asking it to explicitly. (I'd "only" lose comments and group metadata, but that's quite enough, thanks.)
Edit: Of course, just after publishing iPhoto did just that: it lost a week of photos that I'd posted via its uploader. I'm more or less able to recreate them, I think, but I've left broken links and dropped favourites. I hate to have done that to people. (For what it's worth, I think I'm somewhat to blame. See, when iPhoto gets confused, it'll delete its connection, and then restore the image by downloading it from Flickr. However, this evening, before it had finished, I deleted the "images" (actually placeholders). I'm sure that in the past, both iPhoto and myself have done this and both the Flickr and local copies have stayed intact. Today, the Flickr copies were removed.)
So, what now? I could hope that a point release of iPhoto makes it more reliable, but to be honest, I feel like this is actually a Really Hard Problem, and I can imagine that Apple care more about Facebook. Anyway, 8.0.2 doesn't seem to have made the slightest bit of difference, and now I've given up on the whole experiment and reverted to using Flickr Export.
Of course, that don't offer two-way sync either, because previous versions of iPhoto didn't have anywhere to store the metadata, and the current version doesn't document how to². Aperture does have a more expressive API, so Flickr Export for that app does offer syncing (although I suspect not back-filling), and I have other reasons to consider an upgrade (not least, how to handle libraries of RAW files that easily fill a laptop hard drive).
Still, it feels like a lost opportunity. Ah well.
¹ Actually, not quite true: you can fiddle with the "date uploaded" field, but only in the Organizer. It's not exactly drag and drop. Usually I'm fine with that, but then, I'm used to apps that behave themselves. ↩
² Apparently F-Script and PyObjC (and presumably, somehow, ObjC itself) allow you to inspect running apps, so at some point I need to figure out how to use one or more of them to inspect the blobs that I discovered were stored in the SQLite database for Flickr syncing. ↩
2009-04-06
How to use Daytum
Daytum, the personal information tracking site by Ryan Case and Nicholas Feltron, came out of beta just this weekend. I've been using it (on and off) for a while, and a couple of weeks ago I wondered on Twitter if it was just me that couldn't wrap his head around how to use the site. Someone (who's private, so gets to remain nameless) pointed out that there was evidence that I wasn't.
Nonetheless, I'm not the sort to just give up, so I spent a good half an hour poking at the corners of the interface, and I think I've figured out a couple of fairly important, but somehow hidden, UI elements that I think will make the site easier to use for some.
This example will show you how to set up a "miles run" counter, how to backfill data, and introduce you to how to display that data.
First, get a Daytum account, log in, and then "edit your data sets". Create a new counter:

Once you've done that, you'll be presented with a nicely laid out form. Add an appropriate name (the public will never see this), then you'll be prompted to add your first item.

![]()
This item will show up in the user interface, so pick its name well. For our purposes, the only thing this counter is tracking is miles run, so "Miles Run" is an obvious name. As you add the item, you'll see the interface now ask for an amount.
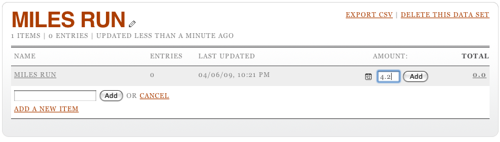
I'm adding 4.2 miles run. Click Add and the total will be update to reflect this. But I didn't just run 4.2 miles; I did that yesterday afternoon. To edit the date, you have to click on the total, then on the pencil icon that appears when you hover over the row that's revealed. This opens up a date editing widget. (Note it's always in US date format. Oh well.)
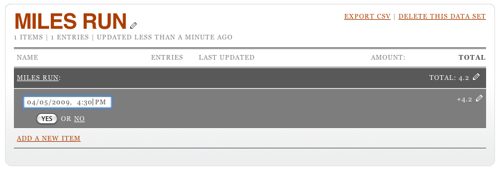
You can also edit the amount by, again, clicking on the pencil at the other end of the row. It turns out that it's possible to set the date and time when adding a row, too: click on the little calendar icon (it says "12" on it) before you submit your amount. This will let you see two rows when you click on the total.
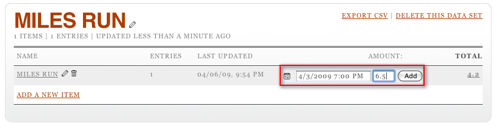
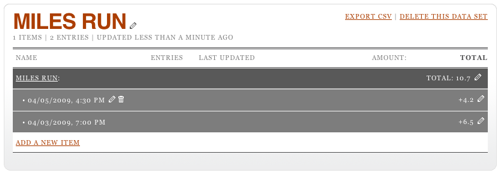
So, now you're adding data happily every time you run, but nobody in the world can see this. For that, you need to go back to your home page on Daytum and add a display.
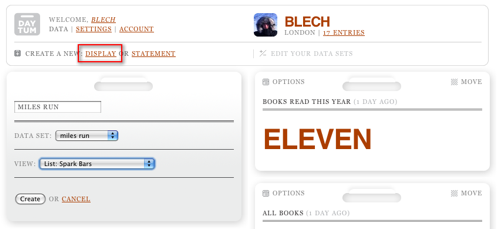
Note that this is where that "data set" name that nobody else sees is used: it ties a display to an underlying counter. You can also play around with different visualisation options; I'm partial to "Spark Bars" but you might prefer something else.

Hey presto, there's your progress. Or, in the case of my completely artificial data, lack of it. However, there's a nice trick here: the ± icon next to the total can be clicked on to allow you to add data directly from the display. You'll also note the same calendar icon, allowing you to back (or forward) date entries.
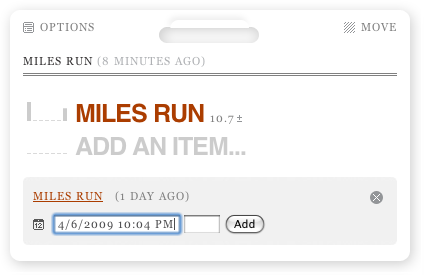
There's one final trick to mention. Once a display's been set up, click on "Options" at the top left and you can get a link direct to that panel.
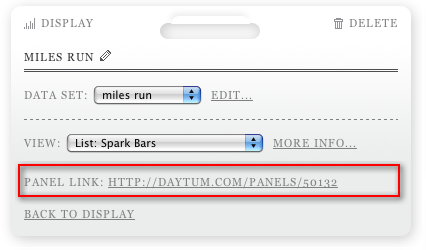
Hopefully this has helped someone else who was a bit confused cut to the heart of the Daytum site.
2009-03-16
Thoughts From the Open Platform
Last November, I was lucky enough to get an invite to the Guardian's first hack day, which commenced with signing an NDA for their forthcoming API. Last Tuesday, I got up early to go to the shiny new Kings Place offices to see the Open Platform launch, and there were three things I wanted to post about it.
The first has been well covered: how open it is. I was initially hesitant about this too, but unlike the sites that have launched APIs until now, which are largely built on user-generated content (for once, the phrase actually fits), the Guardian's opening up content which it's sold rather than given away for nearly two hundred years.
Meanwhile, Winer raises the question "You gotta wonder if when they get out of beta their competitors will be able to repurpose their content. My guess is not" when that was the first question raised in the launch Q&A (and it's been reported since, not least on Roo Reynold's excellent writeup); it was answered (more or less) with a yes. The situation isn't ideal, and I still don't have an API key, but it's a very different beast from an service whose goals include backing up your own content. For now, I'll forgive them.
The second was on the subject of the Data Store, the Guardian's curated selection of "facts you can use", as the title puts it. The spreadsheets are hosted on Google Docs, but to edit them online you have to export them as Excel and then reimport them.
This seems incredible to me now, having been exposed to the joy of GitHub and its easy forking. Why not allow people to spawn editable copies of a spreadsheet, directly linked back to an authoritative source, keeping their own views (including visualisations)? Admittedly, this is a project more for Google (or a competitor to them) than the Guardian, but it'd be great.
(As a side note, I found the post by Simon Dickson on Data Store quite interesting. I did once spend some time grappling with ONS spreadsheets, and found them quite hard to work with. Unfortunately, a quick look at the Guardian's selection shows some of the same problems - heading rows that interfere with columns, for example. Again, a forking model would allow the emergence of semi-canonical clean data sets, which would be great.)
The final point was even more tangentially linked to the Guardian's APIs, but it did spring to mind in discussions (with, I think, Gavin Bell in the immediate aftermath). It arose after talking about the demo Chris Thorpe wrote for the launch, Content Tagger, which combines the Guardian's tags with those in Freebase's ontology and the hive mind's tags from delicious.
As Chris says in his writeup (which is well worth reading), "Tom Coates' vision of the Age of Point-at-Things is fast becoming the age of point at resources and link them all together," and what seems to be linking things together more and more often is the tag.
More specifically, machine tags are foreign keys. (Well, they can be other things, too. But they're very good at that in particular.) For example, I can imagine a script that adds tags to delicious based on the Guardian's tags for their own stories, but prefixed with "guardian:" or "guardian:tag=" so that they don't clutter my tags. Similarly, snaptrip links Flickr to Dopplr, like the popular lastfm: and upcoming: machine tags, while the recently-launched Friends on Flickr Facebook app uses, guess what, facebook:user= machine tags.
Content Tagger doesn't directly use machine tags that way, but it struck me that it might be a useful way to think about them in the future.
In any case, it was a privilege to attend the launch, and I'm happy to have had a few thoughts spurred by it.
2009-02-20
Saving State and Programming
John Gruber just posted one of his (increasingly rare) long-form posts, on the subject of untitled documents, friction, and computers handling the boring things for you. He picks an example from a recently-released piece of software:
BBEdit 9 has a good implementation of such a feature. Once a minute, it silently and invisibly stores copies all open documents. If BBEdit crashes or otherwise exits abnormally (like, say, if the entire system goes down), when next you launch BBEdit, it restores your work to the last auto-saved state.
I agree, it's a great feature. I ranted years ago about saving state in iTunes (an app that Gruber deservedly celebrates for hiding a tedious implemenation detail - the on-disk layout of your files - from the user). The thing that's surprising me is that programmers have become so used to the idea that an application should be a blank state at startup, that they actively think anything else is a bug:
I'm getting a strange behavior in BBEdit 9.1. When I launch BBEdit it mysteriously opens all the files I had open when BBEdit was last quit.
How did we get to this state? If you come back into your office on Monday morning and your papers aren't where you left them, you swear under your breath at the cleaner, not think "oh, good, someone reset my working environment". I don't see any reason why my computer shouldn't be the same as my office desk is: everything should be where (and how) I left it.
I think there's a parallel between dynamic languages and saving state that Gruber doesn't explicitly state: they've both been enabled by all that computing power that twenty-five years of Moore's Law has put into my MacBook that wasn't in the original 128K Mac. Who cares if your language's compiler has to wrap print "hello world"; in all that boilerplate for you? Similarly, writing out a few kilobytes of state information every now and again and reopening a few dozen files at app startup isn't going to kill you (especially when you only restart it once a fortnight).
Thankfully, all that time programmers save by not having to write boilerplate code should give them time to implement state-saving. They'll save even more when frameworks do it for them. Hopefully, by that point, users will expect it, too.
2009-02-17
Aggregation and the Edge
A couple of years ago, I decided that there was something worth building that would be a combination of aggregation and social networking. People had done the first part (I used Suprglu, for example, and you could (and still can) turn Tumblr into an aggregator) and the second bit (at that point, Facebook was rapidly climbing) but the two hadn't really been put together.
Of course, within a few months, not only had Facebook sewn up the market for the casual user, while FriendFeed had emerged and become popular amongst the alpha geeks. I went off and built my own shallow-aggregation front page, while it seemed more than a few people decided the right approach was to cross post from every service to every other one (which annoyed me no end, and made me think that filters will eventually become very important- but that might be another post).
Now I'm beginning to see a new shape of software emerge from people's discussions. Its genesis probably came about after last year's XTech, when Jeremy Keith posted about Steve Pemberton's talk, Why You Should Have A Web Site:
With machine-readable pages, we don't need those separate sites. We can reclaim our data and still get the value. Web 3.0 sites will aggregate your data (Oh God, he is using the term unironically).
The idea lay germinating for a while, but it's emerged back into the spotlight because of the wave of site closures and database losses over the New Year. Users of Pownce found themselves without a site, and Magnolia's bookmarks were lost in a database crash, for example. If you have a deeply-aggregated site - one where you host a local store of data that's also on a remote service, like Phil Gyford and Tom Insam have built - then you, by definition, have a local backup.
I think doing things this way around - using the remote services as primaries, with your own site being fed from, but (if needs be) independent of them - makes the most sense. You can use the social networks of sites like Flickr, which are their strong points.
Now, I'm not there yet. My current site uses only shallow aggregation - I pull in links and posts, but I show them to the user and then forget them. The first step to making a proper site is to build a local database and start backing up to it. This is probably worth doing no matter what - in fact, it's the whole point of Jeremy Keith's most recent journal post - and it turns out I have the seeds of the code I need in the scripts I wrote to generate my 2008 web posting statistics.
I'd already been considering using a key-value or document store rather than an RDBMS for this when I saw Jens Alfke's post on using CouchDB for a "Web 3.0" site (look, it's that term again!) He notes that, while unfinishes, CouchDB looks like it may implement a usable system for replicating data at web scale, so that the social activity could finally move from specific sites to the edge (or at least, our own colos).
Now I'm wondering: is there a space for a piece of user-installable software, like Movable Type or Wordpress, that aggregates their data from sites across the web, and then presents it as a site? If there is, is it even possible to write it in a way that anyone who couldn't have written it themselves can even use it? Can I write it just for myself in the first place? I don't know, but in the next year, I think we'll find out.
2009-02-11
Making App Engine Production Ready
It's probably because I've just subscribed to their weblog, but the Google App Engine team seems to be generating a lot of activity at the moment. In addition, it seems as that the platform itself is getting more attention. As a user of the service, there are some threads in all of that I'd like to tie together.
Most recently, the 1.19 release of the SDK brought urllib, urllib2 and httplib compatibility. This means that the sort of fixed I talked about for snaptrip, where I had to patch Beej's Python Flickr library, is no longer necessary- any web API module should work on GAE without needing any patches or special work on the part of the author.
1.19 also introduces a bulkloader and a remote data API. Personally, I seem to be able to get by without databases for most of the projects that end up live, but for the majority of other developers, a robust backup / restore service is a necessity. As yet, bulkloader is only half of the picture, but it indicates both parts of the problem are getting attention. Finally, 1.19 ups the request and response limits to 10MB from 1; useful for moderately-sized PDFs, for example.
Further away, an earlier post discussed some additions to the App Engine roadmap. For me, by far the most important is the promise of background tasks and task queues, which would be very useful for building a local cache of Flickr data. There's also mention of XMPP, which would be fun, and the ability to receive email, which I can see being useful also.
In the wake of these announcements, I've been asked: "is GAE ready for production?" I'd say the answer lies not with these features (although I'm sure some projects would require them), but with the continued beta status, and more concretely, the inability to pay Google money to use extra computing resources.
Aral Balkan gave an amusing and informative talk at the London Django user group last month, covering his issues with hosting the
conference website on App Engine. While he mentioned workarounds for long-running processes, data portability, and large files, I believe the single key thing that would have made his task easier is the ability to pay Google money to use more nodes, and hence make Over Quota wrnings go away.It is somewhat ironic that Google can evidently scale, and that App Engine is not only designed for scale, but enforces scaling on the design of your application, but that sites hosted on it can't take full advantage yet. Once the current limits go from being a brick wall to a toll gate, the site will be far more attractive for serious work, and I might even recommend it as production-ready.