2013-08-14
intersect.husk.org - a writeup
Ever since Twitter hid at-replies from people who weren't mutual followers, I've had cause to wonder how many people are seeing the conversations I seem to be taking part in.
I remember, even just a couple of years ago, there being a few web sites that let you put in two usernames and see who was following both, but there are two problems with that:
- They were usually really badly designed
- I couldn't find any of them recently
- they never did seem to like the fact that my main account is protected
That being the case, I thought it'd be a good little project to hack on. Fetching and calculating the overlap was pretty straightforward, and I had the idea that I'd like to represent the followers of both users, along with their overlaps, with a Venn diagram. It wasn't too hard to get this drawing with d3, but it took a while to completely straighten out all of the maths.
Once I had the app up and running, I found the real reason there probably aren't any of these services any more: Twitter's API rate limits. In particular, intersect makes a lot of use of the /follower/ids call - understandably, since the whole point is the overlap of followers - which gets 5,000 followers at a time, but is limited to 15 calls per 15 minute window.
What does this mean for a user? Well, if you're following normal-ish people, then you can only look up a few of them every quarter of an hour. After that, the app echoes the error Twitter returns: 'rate limit exceeded'. If you try someone with hundreds of thousands of followers, the app will just fail.
I've thought about putting in a counter, either raw or as a percentage, and also of detecting users who'd require more than a few calls to /followers/ids/ and refusing to work for them. (Alternatively, I could only consider their most recent ten thousand users. I may yet do that.)
For now, though, I seem to have reached a point where I'm happy to stop writing code, finish this write-up, and let the app hang out on Heroku for as long as it wants. If you're curious about the code, it's on Github. Meanwhile, I can happily check that when I have a spirited conversation with @whoisdanw, only sixteen people are likely to be subjected to it.

(Oh, and thanks to Fiona Miller, who did some sterling work on colours, as well as thinking through user interactions, and Tom Insam, who came up with the good idea of colouring the users to match the circles representing their follower counts. They were invaluable in making the site look lovely.)
2010-01-28
Introducing docent
Flickr and galleries
It's now a little over four months since Flickr launched their galleries feature. I liked it as soon as I saw it: it's taken a frequent request ("how can I have sets of favourites?") and delivered something that does the same job, but in a different way. I know some people quibble about some of the constraints, but I like the limited number of photos you're allowed, and generally I've enjoyed creating and browsing them.
Unfortunately, there's a problem: discovering other people's galleries. Aaron Straup Cope is good at bookmarking them on delicious, and there's an Explore page, but neither of those necessarily find things I'd like to see.
The gist of it
Just over three weeks ago, Kellan announced the first API support for galleries, and I quickly created a Python script that would go through all my contacts and fetch their galleries. It was useful, and it turned up a lot of galleries I hadn't seen, but it had two big flaws: nobody else would use it, and it wasn't pretty.
App Engines and data models
I've used App Engine in the past, but that was before the advent of their experimental Task Queue API, and I didn't use the datastore. Using Aaron's gae-flickrapp as a core, I spent about a week's worth of evenings on and off learning how to use both, ending up with the core of docent¹, a small web app.
There are only four kinds of object: dbFlickrUser, from gae-flickrapp, which handles logged in users; Contacts, which have a one-to-one relationship with dbFlickrUsers; FlickrUser, which is an object for a user docent knows about but who isn't necessarily logged in; and Gallery, which stores information about the gallery itself.
What it does
When you first log in, a task is added to a high-priority queue to fetch your contacts from Flickr. The NSIDs² from this call are stored in a single ListProperty in the Contacts object, and then a new task is added to a lower-priority queue. This goes through the IDs one by one, fetching the galleries Atom feed³ and creating the relevant objects (if necessary). This, and the various tasks to update galleries for older users, make up the bulk of the CPU load of the app, and almost all of the Datastore writes.
The big difference between traditional ORMs and the way I'm using the App Engine datastore comes into play here. In an ORM such as Django, a dbFlickrUser would have a many-to-many relationship with FlickrUsers, which would then have a one-to-many relationship with Galleries. The former would require a join table between them. The query to fetch all galleries from a single user would look something like galleries = Gallery.objects.filter(owner__contact_of__nsid=nsid)
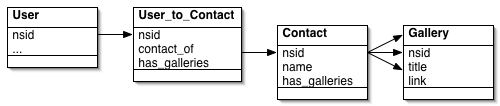
By contrast, in the datastore, Both FlickrUser and Gallery objects have a contact_of ListProperty. As a new user's contact list is examined, their NSID is added to the contact_of list. This is how the pages showing galleries for a contact are built: it's a simple equality test, which is translated behind the scenes to a list-membership test:
galleries = Gallery.all().filter('contact_of =', nsid).fetch(256)
 It took a lot of fiddling to break out of the ORM/SQL mindset, based on joins, but I think I'm happier now I have. On the other hand, keeping the contact_of lists on all the objects in sync is something of an overhead, and the query code isn't significantly easier. There's also a rather severe limitation I only ran across later.
It took a lot of fiddling to break out of the ORM/SQL mindset, based on joins, but I think I'm happier now I have. On the other hand, keeping the contact_of lists on all the objects in sync is something of an overhead, and the query code isn't significantly easier. There's also a rather severe limitation I only ran across later.
Onto the Flickr blog
This was all well and good as I let a few other people at the site; initially close friends, then via a couple of screenshots on Flickr, before inviting a bit more of a burst of users via Twitter. The site seemed to be scaling fine; there was a lot of CPU used fetching contacts, which eventually I managed to optimise by being more selective about updating from the gallery feeds.⁴ In fact, the FlickrUser object is currently pretty much a stub, although I'm thinking of changing that.
However, when docent made the Flickr blog, it hit a serious issue: exploding indexes. The version of the app that was live was doing this query:
galleries = Gallery.all().filter('contact_of =', nsid)
.order_by('-published')
.fetch(offset, per_page)
That extra "order_by" criteria required an additional index, and because it's combined with a ListProperty (namely contact_of), it hit the problem documented in the Queries and Indexes page:
Custom indexes that refer to multiple properties with multiple values can get very large with only a few values. To completely record such properties, the index table must include a row for every permutation of the values of every property for the index.
When I last looked, docent knew about 14,000 or so galleries. While most had small contact_of lists, some no doubt expanded to dozens of people, and so the index was too large to store. As a workaround, I eventually realised I had to abandon sorting in the query and instead use Python, at which point the app started being responsive again. Lesson learnt, the hard way.
Moving On
So, what now? The app is up, and although there are a few errors still happening, they're mainly in background tasks that can be optimised and retried without any impact on users. Personally, it's been a fairly good, if occasionally intense, introduction to App Engine's unique features.
Would I do things this way again in future? I'm not sure. Turning the relationship model on its head hasn't led to an obvious improvement over the ORM+SQL methods I'd use in, say, Django, and while the Task Queue API is very easy to use, it's hard to develop with (since it has to be fired manually locally) and there are other job queue solutions (such as Delayed Job, for Rails, as used on Heroku). On the other hand, even with the heavy load, and not the best of optimisations, docent almost stayed within the App Engine free quota CPU limits⁵, and didn't approach any of the others.
In any case, I'm happy to have produced something so useful, and hope that anyone who tried using it yesterday only to run into errors feels willing to try again. In the meantime, I'm sure there'll be more scaling roadbumps as the site gains users and more galleries are added, but I'm looking forward to fixing them too. Please, try docent out.
(I know comments aren't enabled on this site at the moment. Feel free to add them on docent's page on Flickr's App Garden.)
¹ Why "docent"? Originlly it was the unwieldy gallery-attendant, but Chris suggested the name, based on a term more common in the US than here for the guide to a museum or gallery. ↩
² NSIDs feel like the primary key for Flickr users: in methods like flickr.people.getInfo, it's one of the key pieces of returned information, and it can be used in feeds to fetch information as well as URLs to photos and profile pages.↩
³ Using feeds rather than API calls can be handy. For one thing, they don't count against your API queries-per-second count; hopefully they're cached more aggressively, both via the feedparser library and on Flickr's side so they take less resources.↩
⁴ One nice thing about getting more users is that the likelihood of finding a contact's galleries in the data store already goes up. When I was developing, I had to fetch everything; for the second user, there was some overlap, saving calls. As the site gets bigger, the number of fresh gallery fetches should keep fairly low.↩
⁵ Since I last wrote about App Engine, it's grown the ability for users to pay for resources beyond the free quota levels. I decided to do this when I hit about 55% of my CPU quota, and the app did indeed reach about 120% yesterday. I don't have a bill yet but I expect it to be under $0.50, which is fine.↩